이번 챕터에서는 우선 메모리 할당시 실제 할당되는 크기에 대해 간략하게 이야기한 뒤,
vector, list, set(map)에 요소를 추가할 때 발생하는 비용과 바이트 정렬(alignment)을 곁들어
실제로 사용되는 메모리 크기에 대해 이야기한다.
vector, list, set(map)에 요소를 추가할 때 발생하는 비용과 바이트 정렬(alignment)을 곁들어
실제로 사용되는 메모리 크기에 대해 이야기한다.
신참 질문
new나 malloc으로 메모리 n 바이트 할당 요청시 실제로 할당되는 크기는 정확하게 크기 n과 일치하는가?
그렇지 않다면, 그 이유는 무엇인가?
new나 malloc으로 n 바이트의 메모리를 요청했을 때, 실제로는 '적어도' n 바이트의 메모리를 할당하게 된다.
즉, n 바이트 이상의 메모리를 사용하게 될 수도 있는 것이다.
이는 메모리 관리자가 요청에 약간의 추가 비용을 부담하기 때문이다.
일반적으로 그러한 추가 부담에는 1) 관리를 위한 것과 2) 조각 크기에 의한 것이 있다.
1. 관리를 위한 추가 부담
할당된 메모리에 대해 delete나 free 요청이 발생해 메모리 관리자가 메모리 해제를 수행하려면,
원래 할당했던 메모리의 크기를 정확하게 알고 있어야 한다.
메모리 관리자가 그러한 정보를 기억하는 일반적인 방식은 메모리를 할당할 때
할당된 메모리 블록 첫 부분에 그 블록의 크기를 써 두고,
할당 요청 코드에게는 그 크기를 쓴 부분 이후의 메모리 주소를 반환한다.
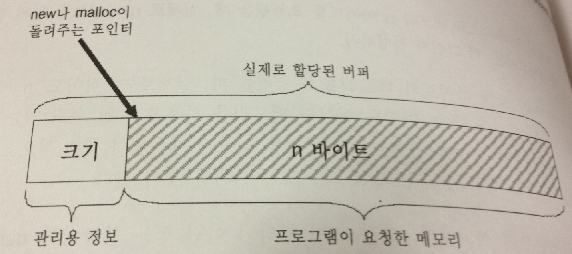
2. 조각 크기에 의한 것
추가적인 정보를 저장하지 않는다고 해도, 메모리 관리자는 요청된 것보다 더 많은 바이트들을 할당한다.
이는 일반적으로 메모리가 특정한 크기의 조각 단위로 할당되기 때문이다.
예를 들어, 일부 플랫폼들은 하드웨어의 제약이나 성능 상의 이유로 해서 데이터들을 특정한 바이트 경계들에 맞게 배치한다.
이를 바이트 정렬(byte alignment)이라고 부르는데, 이 때 바이트 경계에 맞추기 위해서 객체의 자료 끝에 추가적인 바이트들을 채우게 된다.
바이트 정렬을 하는 기준은 다음과 같다.
1) 32비트 환경에서 바이트 정렬은 4 bytes -> 2 bytes -> 1 byte 순이며,
2) 64비트 환경에서는 8 bytes -> 4 bytes -> 2 bytes -> 1 byte 순으로 바이트 정렬이 이루어진다.
4 bytes -> 2 bytes -> 1 byte 순서라는 것은...
우선 4 bytes 정렬을 하려고 봤더니 4 bytes 짜리가 하나도 없으면,
그 다음엔 2 bytes 정렬을 위해, 2 bytes 짜리를 찾아본다.
이 때 2 bytes 짜리가 있으면 2 bytes 정렬을 하는 것이다.
그럼 char 형은 1 byte 이므로, 바이트 정렬을 위해 1 byte 패딩이 붙는다.
만약, char 형 변수만 두 개가 있으면?
4 -> 2 -> 1 byte까지 내려왔기 때문에 1 byte 정렬이 되고, 패딩 없이 1+1 = 2 bytes만 소모하게 된다.
보통의 내장 C 스타일 배열도 이런 정렬 요구에 영향을 받으며, 실제로 그러한 요구는 sizeof(struct)에도 기여한다.
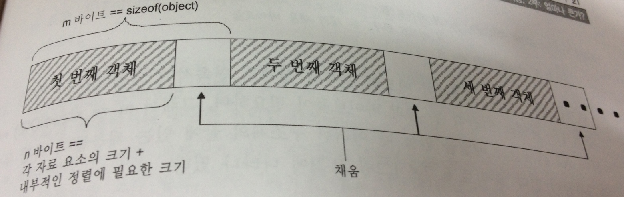
바이트 정렬을 위한 패딩이 어떻게 일어나는지 아래 예제를 통해 살펴 보자.
struct Sample
{
char a;
long b;
char c;
};위 Sample 구조체의 크기 sizeof(Sample)은 얼마일까?
char(1) + long(4) + char(1)의 멤버를 가지므로 도합 6바이트로 보이지만, 실제 메모리는 12바이트가 들어간다.
char(1) + long(4) + char(1)의 멤버를 가지므로 도합 6바이트로 보이지만, 실제 메모리는 12바이트가 들어간다.
struct Sample
{
// sizeof(long) == 4이며, 아래 멤버들은 long에 맞춰 바이트 정렬이 된다.
// 즉, 4 바이트가 되지 않는 녀석들에 대해 정렬을 위한 바이트 패딩이 붙는 것이다.
char a; // real (1) + padding (3)
long b; // real (4)
char c; // real (1) + padding (3)
};만약 가운데 멤버가 long 타입이 아닌 __int64 타입이라면, 8바이트 정렬이 들어가 총 24바이트의 메모리가 소요된다.
그럼, 옆으로 살짝 비켜서서 위와 같은 바이트 정렬을 위한 메모리 패딩을 1) 줄이거나 2) 없애는 방법에 대해 알아보자.
그럼, 옆으로 살짝 비켜서서 위와 같은 바이트 정렬을 위한 메모리 패딩을 1) 줄이거나 2) 없애는 방법에 대해 알아보자.
1. 줄이는 방법
struct Sample
{
// 멤버 배치 순서를 바꾸어 총 6바이트 패딩을 2바이트 패딩으로 줄였다.
long b; // real (4)
char a;
char c; // real (1+1) + padding (2)
};게다가, real - padding - real - real - padding의 구조보다 real - real - real - padding의 구조로 가는 것이 훨씬 좋다.
따라서, 쓸데없는 메모리 패딩을 줄일려면 바이트 정렬을 고려해서 멤버 변수들을 배치하는 습관을 들이는 것이 좋다.
2. 없애는 방법
바로 #pragma pack을 사용하는 방법이다.
#pragma pack(push, n)의 의미는 바이트 정렬 기준을 n 바이트로 잡겠다는 의미이다.
이를 사용하여 #pragma pack(push, 1)로 하면, 1바이트 정렬을 사용하여 빈 공간없이 메모리에 올라간다.
#pragma pack(push, 1) // 또는 #pragma pack(1)
struct Sample
{
char a;
long b;
char c;
};
#pragma pack(pop) // 또는 #pragma pack()그러면, 쓸데없는 메모리를 붙여주지 않는 #pragma pack(push, 1)을 계속 쓰면 어떻게 될까?
최대한의 성능을 내기 위해 해당 머신에 맞는 바이트 정렬을 하는 것인데, 이를 1로 줄여버리면, 성능 하락이 발생할 수 있다.
그렇기에, 메모리 양을 엄밀히 제어해야 되는 부분이 아닌 곳에서는 기본 바이트 정렬을 하도록 다시 풀어주는 것이다.
보통 패킷 데이터 같은 것들은 크기를 조금이라도 줄일려고 노력하기 때문에, 위와 같이 사용한다.
고수 질문
동일한 개수의 타입 T 객체를 담는다고 했을 때, STL 표준 컨테이너들은 각각 어느 정도의 메모리를 추가로 사용할까?
그럼 vector, deque, list, 트리 형태의 set/map 컨테이너들에 대해 하나씩 살펴보자.
1. vector
vector는 내부적으로 T 객체들의 연속적인 C 스타일 배열을 저장하기 때문에 요소가 추가될 때마다 추가 부담은 없다.
2. deque
deque는 내부 저장소가 여러 조각들로 나누어진 vector라고 할 수 있다.
deque는 객체들을 조각 별로, 또는 "페이지" 별로 나누어서 저장한다.
페이지의 크기는 표준에 명시되어 있지 않으며, 기본적으로는 T 객체의 크기에 영향을 받되, 표준 라이브러리 구현마다 조금씩 다르다.
이러한 페이징 방식에서, deque는 페이지 당 다음 페이지를 가리키는 포인터(next page pointer) 하나를 저장한다.
따라서, 이를 요소 단위로 계산하면 아주 적은 양이 된다.
3. list
list는 T 객체를 담는 노드들이 이중으로 연결되어 있는 리스트로 구현이 되어 있다.
따라서, 요소가 추가될 때마다 prev/next 두 개의 포인터 비용을 추가 부담한다.
4. set/map
역시 T 객체를 담는 노드 형태로 저장하며, parent / left-child / right-child를 가리키는 세 개의 포인터가 필요하다.
위 내용들을 표로 만들어 보면 추가 비용은 다음과 같다.
위의 표만 보면 list가 set 보다 포인터 하나를 덜 쓰기에 추가 부담 비용이 33% 적은 것으로 보인다.
하지만, 아래와 같은 환경에서라면 실제 사용되는 메모리 크기의 비교는 조금 달라질 수 있다.
1. 환경은 32비트이다. 즉, 포인터는 4바이트
2. sizeof(string)은 16 바이트라고 가정한다. 여기서 얘기하는 string의 크기는 순수 string 클래스의 크기이다.
(참고로, vs2010에서는 string 클래스의 크기가 32비트에서는 32바이트, 64비트에서는 48바이트이다)
3. 기본 메모리 할당 전략은 고정 크기 할당이다. Granularity는 16 바이트 단위이다.
이제 다양한 자료형을 담은 후, 위 세 가지 단서들을 적용시켜 보면,
고정 메모리 할당의 블럭 크기와 바이트 정렬에 의해 다음과 같은 결과 표가 만들어 진다.
대부분의 고성능 메모리 관리자는 다양한 크기에 대해 준비된 고정 크기 할당 방식을 사용한다.
M$의 LFH(Low Fragmentation Heap)도 그렇고 게임 서버에서 흔히들 직접 짜서 사용하는 메모리 관리자 역시 보통 위와 같이 고정 크기 할당 방식을 사용한다.
특정 상황에서 자료 구조를 선택할 때 메모리 사용량이 중요한 기준이라면,
이런 종류의 분석을 수행해보고 컨테이너 별 차이가 실제로 얼마나 되는지를 확인해 볼 필요가 있다.
가끔은 생각보다 차이가 적을 수도 있는 것이다.
최대한의 성능을 내기 위해 해당 머신에 맞는 바이트 정렬을 하는 것인데, 이를 1로 줄여버리면, 성능 하락이 발생할 수 있다.
그렇기에, 메모리 양을 엄밀히 제어해야 되는 부분이 아닌 곳에서는 기본 바이트 정렬을 하도록 다시 풀어주는 것이다.
보통 패킷 데이터 같은 것들은 크기를 조금이라도 줄일려고 노력하기 때문에, 위와 같이 사용한다.
고수 질문
동일한 개수의 타입 T 객체를 담는다고 했을 때, STL 표준 컨테이너들은 각각 어느 정도의 메모리를 추가로 사용할까?
그럼 vector, deque, list, 트리 형태의 set/map 컨테이너들에 대해 하나씩 살펴보자.
1. vector
vector는 내부적으로 T 객체들의 연속적인 C 스타일 배열을 저장하기 때문에 요소가 추가될 때마다 추가 부담은 없다.
2. deque
deque는 내부 저장소가 여러 조각들로 나누어진 vector라고 할 수 있다.
deque는 객체들을 조각 별로, 또는 "페이지" 별로 나누어서 저장한다.
페이지의 크기는 표준에 명시되어 있지 않으며, 기본적으로는 T 객체의 크기에 영향을 받되, 표준 라이브러리 구현마다 조금씩 다르다.
이러한 페이징 방식에서, deque는 페이지 당 다음 페이지를 가리키는 포인터(next page pointer) 하나를 저장한다.
따라서, 이를 요소 단위로 계산하면 아주 적은 양이 된다.
3. list
list는 T 객체를 담는 노드들이 이중으로 연결되어 있는 리스트로 구현이 되어 있다.
따라서, 요소가 추가될 때마다 prev/next 두 개의 포인터 비용을 추가 부담한다.
4. set/map
역시 T 객체를 담는 노드 형태로 저장하며, parent / left-child / right-child를 가리키는 세 개의 포인터가 필요하다.
위 내용들을 표로 만들어 보면 추가 비용은 다음과 같다.
| 컨테이너 | T 당 추가 부담 | 추가 부담 바이트 수 |
| vector | 추가 부담 없음 | 0 |
| deque | T 당 추가 부담 거의 없음 | 0 < x < 1 |
| list | T 당 포인터 두 개 | 32bit : 8 64bit : 16 |
| set | T 당 포인터 세 개 | 32bit : 12 64bit : 24 |
| map | pair<const Key, T>당 포인터 세 개 | 32bit : 12 64bit : 24 |
위의 표만 보면 list가 set 보다 포인터 하나를 덜 쓰기에 추가 부담 비용이 33% 적은 것으로 보인다.
하지만, 아래와 같은 환경에서라면 실제 사용되는 메모리 크기의 비교는 조금 달라질 수 있다.
1. 환경은 32비트이다. 즉, 포인터는 4바이트
2. sizeof(string)은 16 바이트라고 가정한다. 여기서 얘기하는 string의 크기는 순수 string 클래스의 크기이다.
(참고로, vs2010에서는 string 클래스의 크기가 32비트에서는 32바이트, 64비트에서는 48바이트이다)
3. 기본 메모리 할당 전략은 고정 크기 할당이다. Granularity는 16 바이트 단위이다.
이제 다양한 자료형을 담은 후, 위 세 가지 단서들을 적용시켜 보면,
고정 메모리 할당의 블럭 크기와 바이트 정렬에 의해 다음과 같은 결과 표가 만들어 진다.
| 기본 노드 자료 크기 | 실제 크기(바이트 정렬 및 블록 크기) | |
| list<char> set<char> |
9 13 |
16 16 |
| list<int> set<int> |
12 16 |
16 16 |
| list<string> set<string> |
24 28 |
32 32 |
대부분의 고성능 메모리 관리자는 다양한 크기에 대해 준비된 고정 크기 할당 방식을 사용한다.
M$의 LFH(Low Fragmentation Heap)도 그렇고 게임 서버에서 흔히들 직접 짜서 사용하는 메모리 관리자 역시 보통 위와 같이 고정 크기 할당 방식을 사용한다.
특정 상황에서 자료 구조를 선택할 때 메모리 사용량이 중요한 기준이라면,
이런 종류의 분석을 수행해보고 컨테이너 별 차이가 실제로 얼마나 되는지를 확인해 볼 필요가 있다.
가끔은 생각보다 차이가 적을 수도 있는 것이다.
동적 메모리 할당과 여러 컨테이너들의 실질적인 공간 비용을 확실히 파악하자
'책 스터디' 카테고리의 다른 글
| [Exceptional C++ Style] 23. new와 예외, 2부 : 메모리 관리의 실질적인 문제들 (0) | 2023.04.10 |
|---|---|
| [Exceptional C++ Style] 22. new와 예외, 1부 : 여러 종류의 new (0) | 2023.04.10 |
| [Exceptional C++ Style] 19. 파생된 클래스들에 대한 규칙 강제 (0) | 2023.04.10 |
| [Exceptional C++ Style] 18. 클래스 가상성 (0) | 2023.04.10 |
| [Exceptional C++ Style] 16. private는 얼마나 비공개적인가? (1) | 2023.04.10 |